My devs are always refactoring! why? [part-1]
On Sat, 21 May 2022, by @lucasdicioccio, 2268 words, 0 code snippets, 4 links, 9images.
This article is the first in a series of articles on refactoring and is focused on discussing what is the “scope” of a project and how the dynamics of the scope affect a project.
From a non-developer viewpoint, it may be hard to connect with developers who are always refactoring. I wrote this article to fill some gap I observed a number of times with non-technical stakeholders worried that tech teams where “always refactorin’”. Cannot developers refactor once and move to something more useful?
We must discuss some key dynamics of projects before being able to fully-appreciate topics like what is a refactoring. In particular, we need to be clear about the effects how changes in scope of projects affects the delivery. Thus in this article we’ll have a refresher on what development looks like: a non-linear and discontinuous process.
A refresh on the development process
The main tangible output of software development is software: an increased amount of lines of code, extra kilobytes of configurations, a flurry of new packages and services. All these deliverables need to be organized, cleared of bugs, key limitations need to be documented. Meanwhile, new business questions are raised, technical questions are raised, and hairbrows are raised too 🤔.
Two key characteristics we can emphasize are the fact that developing software is agglomerative and non-linear.
The development process is agglomerative
We write software to fill a given vaccum, to address a set of problems. The amount of vaccum to fill is the scope of the software.
Most software features will require a similar set of technical steps (e.g., writing tests, writing a data schema, writing an API provider or consumer, performing some quality-assurance). Thus it makes sense to categorize these technical steps as layers of work. A single developer can work on a single step at a time. Also developers will specialize into some of these layers, forcing the project management to get some ordering between technical steps. For two different features the steps may not have to share the same ordering, however it’s generally the case that there is some bottom-up sequence in a vertical fashion.
To fill a scope, you need many features, which means that if we collect all the steps for all features, we get a tiling of tasks to fill a given scope.
Graphically you could display that as a set of tiles, each tile corresponding to a technical unit for a given feature.
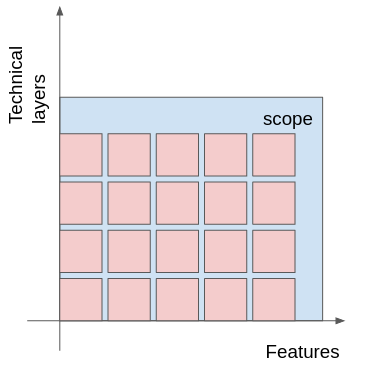
This model is a simplification of real-world projects, in real-world projects you have more dimensions to consider and you do not need to fill a full-rectangle as some features may not have the same requirements. I believe this model is good for a number of reasons: first, this model serves the purpose of illustration and the model is complex enough to make my point, second the model is simple enough to allow making graphical visualisations, finally we could say that not having the same requirements just means that the requirements exists but takes zero effort to fill.
To fill a scope, you have thus two broad strategies:
- follow the horizontal axis: focus on some technical layer, assuming that batching everything together is gonna be more efficient. For instance, it is easier to write database schemas when you know all requirements, and is sensible when all requirements are laid out.
- follow the vertical axis: deliver one feature and then move to the next one, assuming that getting some subset of the scope early is a favourable outcome (early revenues, first-mover advantage, reduce pressure from the C-suite)
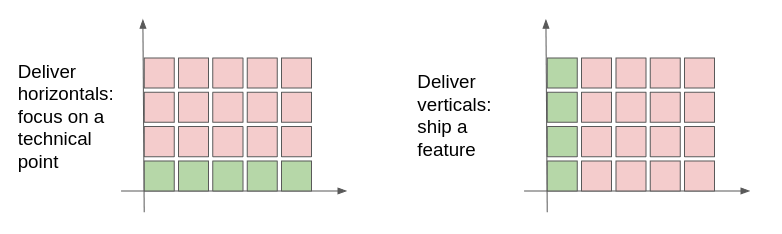
In modern software practices, it is admitted that the vertical is best as the scope is too hard to discover upfront. We’ll discuss scope changes in the next section though.
Whether one writes code along verticals or horizontals, both strategies eventually accumulate code, configurations, packages, documentations and what not. Thus overall software projects inflate and agglomerate. As time passes, gaps are filled, two opposing forces are at play:
- the agglomeration of software is more and more complex and friction drags your developers down
- developers get more experienced on the project and find or build ways to accelerate the delivery
Which of these forces is winning will determine the fate of your project. In particular, too much friction or not enough time spent on accelerating will lead to losing momentum. If your team loses momentum, your project is doomed to fail, if your team gains momentum… you get to play for longer.
If you are lucky enough to play longer, your project will accumulate features. On top of features, software projects also accumulate bugs, customer tickets, and are shaked by changes in the scope of the problem. In short, the evolution of software projects is erratic, with non-linearities, asperities, and discontinuities.
The development process is discontinuous and not linear
Let’s assume your team has been working on a project for some time now. You are roughly half-done. Let’s illustrate it graphically.
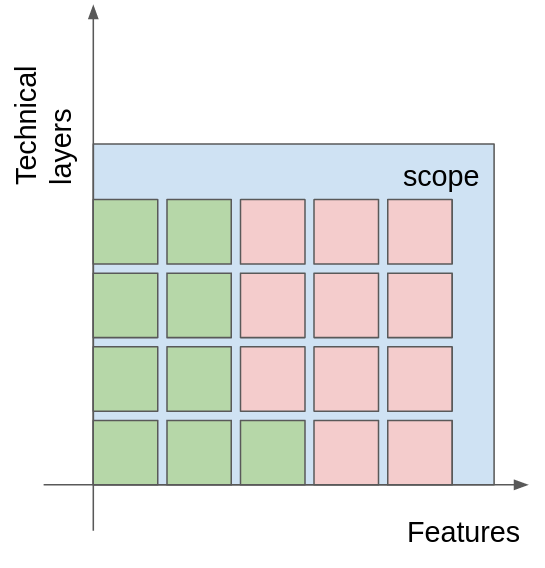
You have shipped (in green) two verticals and one fourth of third vertical as illustrated in the following picture. Remains a backlog (rose) of three fourth for the third vertical plus two full verticals.
When changes of scope occur, two things can happen:
- the scope deflates: this is so rare we won’t dicuss it at length here, softwares allows you to isolate dead weight like un-needed features somewhat easily; however if some feature drags you down you should spend some time cleaning it out (in a refactoring hehehe)
- the scope inflates: this is the typical scenario, software often risk something named feature creep where we want to support so many things that the complexity exploses compared to the team capacity
Changes in the scope of a project are not without consequences on your project.
Effects of scope changes
In this essay we are looking at two dimensions of the scope: features and technicals. The scope changes may be blurry. Although scope may change in both dimensions at a time, it is still valid to studying both dimensions independently. Also, individual tasks are not well-defined boxes, when we zoom on a single task, we realize there is more to it as each task can itself be a small project with its own varying scope.
New features
New features are the routine of software projects. As your system collects more data, as business discussions uncover new pain-points and opportunities, new features are needed.
Graphically, we can illustrate the new features has new verticals that we append.
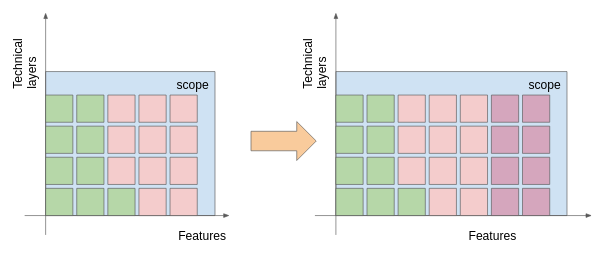
I used a slightly darker red to distinguish the verticals corresponding to the new features. In this situation, the main problem that arises is whether to prioritize iterations on the new features or not. If the prioritization is very high, you may even pause the current vertical where it is.
One key thing to remark is when scope grows horizontally, the software is still deemed perfectly adequate. Thus, whatever value delivered is not at risk and life is good as the future will be a continuation of what worked. Vertical changes are bit more annoying.
New technical requirements
You know where we’re aiming at. Technical requirements changes are disruptive. Such changes can either have endogenous causes (e.g., you have a reached a point where there are too many defects and you need to increase testing) or exogeneous causes (e.g., regulatory changes like the GDPR).
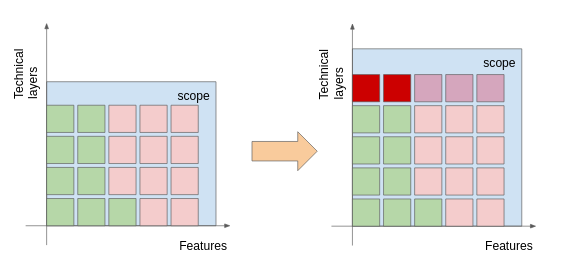
As the technical landscape changes, we need two colors to disinguish what happens to software that exists and is shipped (crimson red) and future software that you will write later (middle-tone red).
The later a vertical change of scope occurs, the larger the impact on your backlog. A late vertical scope change is like a late realization that you were partying on borrowed money. I also like the image of realizing that you were playing in easy mode after subscribing to a video-game tournament: you’re set for some reckoning.
For future verticals, you have one simple decision to make: cut or keep in scope. Cutting an already-started vertical will incur a sunk-cost. Thus, beware the sunk-cost fallacy.
For existing verticals, I picked crimson red for a good reason: new technical requirements are difficult to retrofit. Here you have three broad choices:
- (a) dropping already-shipped verticals
- (b) fill the gap for previous verticals
- (c) ignoring the new requirements for previous verticals. You can make a different decision for each vertical.
Dropping the whole vertical (a) may not be just a sunk-cost but a visible cost as some customer already relies on the corresponding feature.
Filling the gap for a vertical (b) can be hard to sell to other stakeholders as you are not solving new problems. You also need to prioritize these new tasks and consider delaying the ongoing vertical.
Ignoring new requirements (c) may be sensible, but as scope will continue to grow vertically you may just be post-poning the choice (with an increasingly gap to fill to put in balance with dropping an even older vertical).
Summarizing, vertical scope changes are dangerous for projects as they force difficult choices and have compounding effects.
The scope is a fractal
Another problem of software projects is how fractally complex they end up. Individual tasks often have no good “definition of done”. A whole vertical may have some, but individual tasks are left to implementers. Which means developer will likely need to experiment around.
Overall, individual tasks themselves are small projects with a scope. Oftentimes we realize that there is some an abundant amount of details and extra technical bits and internal features to implement. Anticipating whether a task has enough scope to be split upfront is a difficult betting game.
When picking a single task and zoom-ing in, we often can formulate the scope of the task. Within this contour, we may lay down verticals and horizontals like we did for our project earlier. For instance, if the whole task is to add some visual representation of some statistics for a customer, the sub-tasks may be about defining edge cases, verifying against historical data, deciding to present a single statistics or an evolution in time etc. Overall a seemingly simple feature in itself can have a rich scope. If we keep zooming, the code organization, making sure that business rules are decoupled from glue code and so-on and so forth also are mini-scopes within a task substasks.
Graphically we can give a feeling of what it means by zooming on a task as follows:
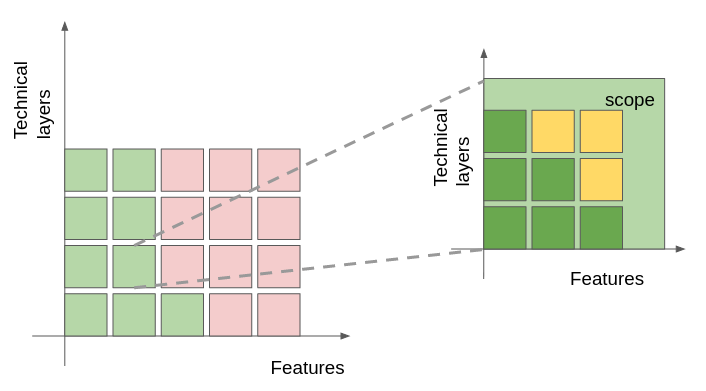
A result of this fractal complexity is that there is no definite answer to say a given task has ended. A hand-wavy rule may be to say a task is mark as done when “enough” of the scope of the task is actually covered. If we try to put numbers, in our case we could define that a task is green when a majority of the subtasks are green. In our example a tile has nine sub-tasks. Which means that the task is done when at most four tasks are “skipped” (yellow) – which we distinguish from “not encountered yet” (rose).
Such a rule is reasonable, and individual tasks may be left in various patterns. Some tasks will have led to code that is complete in many aspects. Some others will have a few edge cases unhandled. Some patchy tasks will have disorganised code but it does the job. Often, the documentation and tests are lacking, and so on and so forth.
Overall, our project is a mosaic that can be scrutinized at a variety of resolutions. Non-developers stakeholders will look at the big-picture™️ of the project and with coarse granularity. Looking at a low-resolution you may get the impression that tasks are fully-done and indeed the project delivers features. However if you had the possibility to increase the resolution of the whole project, you would see the delicate complexity of feature deliveries. We can illustrate this with our example by replacing each task by a set of smaller tasks. We replace every box by nine smaller boxes and we keep the rule that “to make the tile green, we need at most four yellow”.
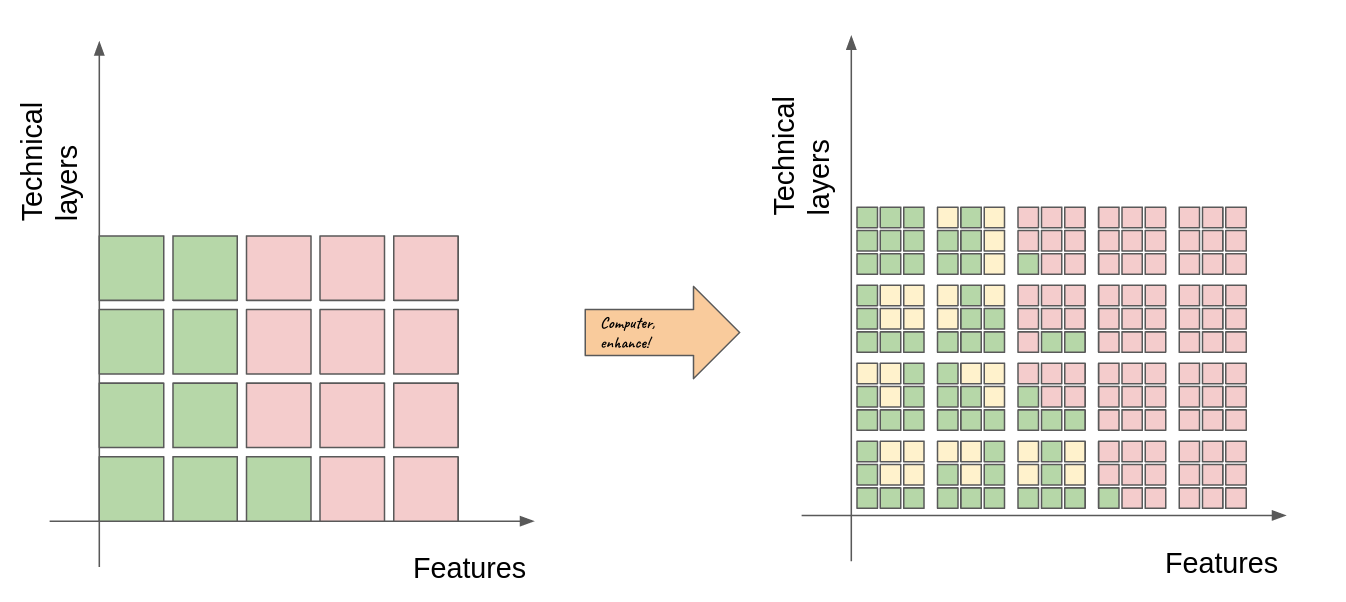
This picture shows that looking closely we may realize that our shiny project where everything is on track actually has a number of holes like a good Emmental cheese. Projects with partially-delivered tasks is the normal life of software, thus it is not a immediate cause of concern (and Swiss cheese is delicious). However it is important to understand the dynamics of the system.
Developers have to live in the reality of high-resolution projects, and the cavities left behind to progress on the project may cave-in as the time passes. Indeed, remember that each task in the project has a scope that may inflate (often) or deflate (rarely). If it occurs that an already-shipped feature has a vertical or horizontal scope change, then we also must make a choice between dropping a task or filling-it at 50% again. The extra difficulty is that if you drop or postpone for too long, a task that is green now will become red. Let’s illustrate again on our high-resolution picture: assume that scope changes affect two already-shipped verticals at the second horizontal-layer.
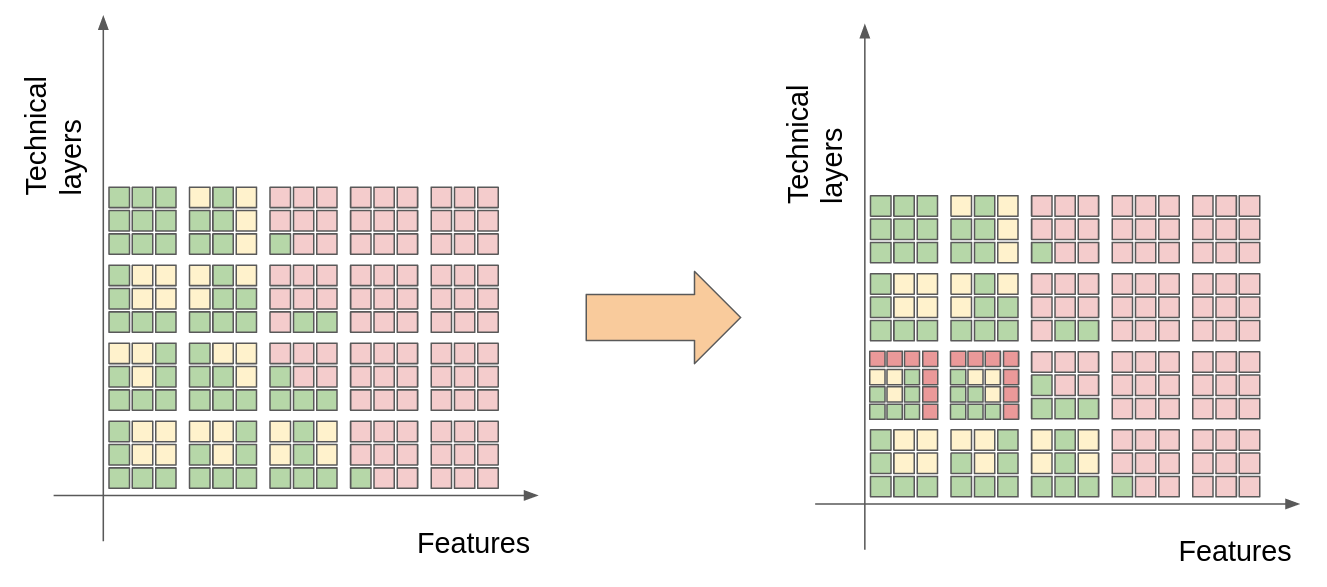
Here both affected tasks used to be filled six out of nine sub-tasks (67%) and are now filled six out of sixteen (38%)! Such a situation is dangerous. Figuratively, two of the already-shipped verticals are deemed unsatisfactory and your project risks a figurative cave-in.
Summary
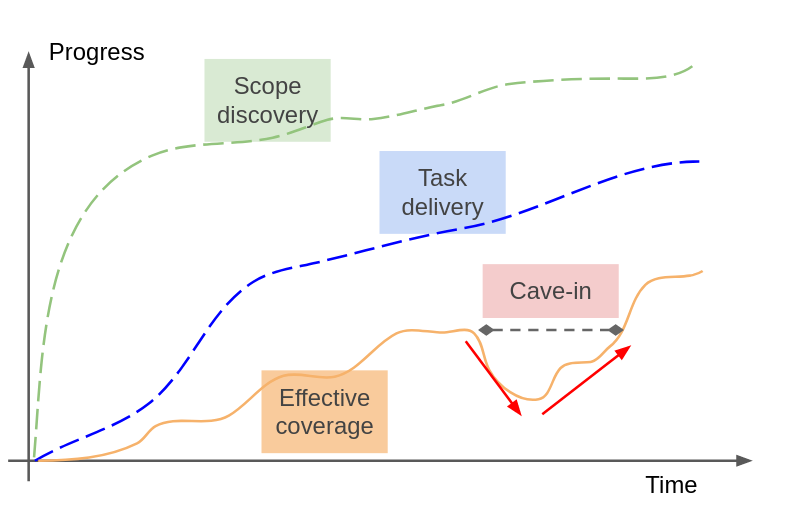
We’ve studied a simple model of software project which is split into tasks to fill a given scope. Project scopes can be described along a number of axes, we focus in particular on the feature-scope (verticals) and on the technical-scope (horizontals). Adding a new vertical has low impact besides prioritization. Adding a new horizontal forces to cut scope or heavily de-prioritization of ongoing features.
Scope is discovered as the project progresses: the scope inflates. Beginning of projects often have a steep inflationnary phase and then the scope accrues more requirements at a lower rate as the project matures. Occasionally, the scope deflates. As delivery of tasks progresses, features get shipped and the coverage of the scope effectively grows in increments. When the scope changes, you risk a cave-in effect where already-shipped features are no-longer passing the bar can no longer be considered as filling the user needs.
All of this can be summarized in the following picture.
In the next article, which we can expect in a few weeks (meanwhile you can see the progress in draft), we’ll discuss what refactorings are and how they help avoid cave-ins.
This article also now has an accompanying micro-application at Scope Explorer.